A lot has happened for Pyston lately; here’s a brief update.
CMake Support
Daniel Agar has taken our hand-written Makefile and converted much of it to CMake. Right now the two build systems live side-by-side, but the plan is (assuming everyone likes it) to switch over entirely to CMake.
There were some changes that affect the Makefile-based build; if you’re setting up a new environment you should be able to just follow the updated instructions. If you have an existing environment, there’s a set of one-time steps you have to take:
$ git pull $ mv src/Makefile.local Makefile.local $ make clean
pypa Python Parser
Vinzenz Feenstra has contributed pypa, a new parser for Python. A new parser is a sensitive issue, so it’s currently being run as part of our test suite but isn’t turned on by default. If things continue to go well with it, we’ll switch over to it from our current parser.
Our existing parser shells out to CPython to do the parsing, which serializes the AST and sends it back to Pyston. Not only is the process inelegant, but it incurs a pretty hefty overhead per file or expression we want to evaluate. The new parser should help a lot, and also looks well-factored so it should be possible to use in other projects as well.
AST Interpreter
Marius Wachtler has written an AST interpreter for us, which has now replaced our old LLVM interpreter. Our old tiering process was to convert all Python into LLVM IR, and then run that IR through various LLVM tiers (interpreter, -O0 compiler, -O3 compiler). This worked fine, except that the main overhead in this process was converting the Python AST to LLVM IR. With the AST interpreter, we can avoid this expensive process for the majority of our code.

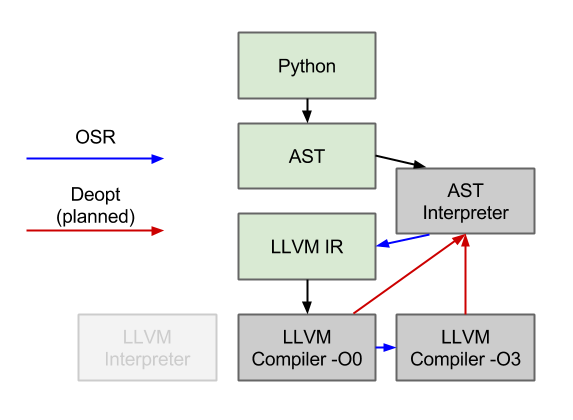
Currently, though, the new AST interpreter is slower to execute than the LLVM interpreter — which was surprising to me, since the LLVM IR is quite low level and not designed for interpretation. The LLVM interpreter does have a few advantages, though: 1) it happens after (very simple) type specialization, which means that it is able to elide dynamic dispatches, and 2) the pointer-based SSA in the LLVM IR is faster to manipulate than the string-based Python AST.
Thankfully, the AST interpreter is significantly faster to start up, as we hoped. Unfortunately though, for one of the cases we were hoping to improve (sre_parse._parse), the function ends up being hot enough to escape the interpreter and incur the compilation cost. As future work, we need to improve the performance of the interpreter so that we can keep more code in it, and also lower the overhead of our compilation tier.
In the works
The rough goal for the rest of the year is to start doing well on the rest of the PyPy benchmark suite. The are two main parts to that:
- Be able to run them quickly.
On the compatibility side, we need to support one more language construct (exec) and a number of additional extension modules.
On the performance front, there are two main things we’re focusing on. The first is reducing our startup time, much of which comes currently from sre_parse._parse (via “import optparse”). The AST interpreter is key to this, as well as some other things we’re going to work on such as swapping the LLVM register allocator.
The other performance aspect we’re working on is better speculations. We have all the parts we need now (AST interpreter and frame introspection) so we have started working on a new tiering framework that will let us speculate on events such as integer non-overflow.
Unrelated to any benchmarks, we are also trying to get Pyston running on OSX. We have a branch that builds, runs through startup, and then segfaults somewhere. I’m currently working on getting a working debugger on OSX to continue the porting.
So, things are still moving quickly, but there’s still a lot to do! I’ve kept the Github issues list up to date with available projects and tasks, and I created a new tracker task that lists the various benchmarks that we don’t support yet as well as what we need to get them running. Please feel free to dive into any of them or to send an email to pyston-dev@pyston.org with any questions.
