In this blog post I want to briefly describe a new feature which landed recently inside Pyston and which also touches one of the most often mentioned feedback we receive: A lot of people are under the impression that LLVM is not ready to be used as a JIT because of the main focus as a static compiler where fast code generation time is not as important as in the JIT usage.
While I agree that an LLVM JIT is quite expensive compared to baseline JIT tiers in other projects we expect to partly mitigate this and at the same time still take advantage of the good code quality and advanced features LLVM provides.
We observe that a lot of non benchmark code consists of dozens of functions which are hot enough that it makes sense to tier up to the LLVM JIT but the small amount it needs to JIT a single functions adds up and we spend a significant time JITing functions when starting applications. For example starting the pip (the package manager) takes currently about 2.3secs, from those we JIT 66 python functions which takes about 1.4secs. We noticed that from the 1.4secs JITing functions about 1.1secs are spend on optimizing and lowering the LLVM IR to machine code (instruction selection, register allocation, etc) and only a much smaller amount of time is spend generating the LLVM IR. We then thought that the best solution is to cache the generated machine code to disk in order to reuse it the next time we encounter the same function (e.g. on the next startup).
This approach is a little more complicated than just checking if the source code of a function hasn’t changed because we support type specializations, OSR frames and embed a lot of pointers inside the generated code (which will change). That’s why we choose (for now) to still generate the LLVM IR but after we generated it we will hash the IR and try to find a cached object file with the same hash. To overcome the problem that the generated code is not allowed to contain pointers to changing addresses I changed Pyston to emit IR which whenever it encounters a pointer address (e.g. a reference to non Python unicode string created by the parser) generates a symbolic name (like an external variable) and remembers the pointer value in a map.
Here comes the advantage of using the powerful LLVM project to JIT stuff – it contains a runtime linker which is able relocate the address of our JITed object code. This means when we load an object we will replace the symbolic names with the actual pointer values, which lets us reuse the same assembly on different runs with different memory layouts.
Results
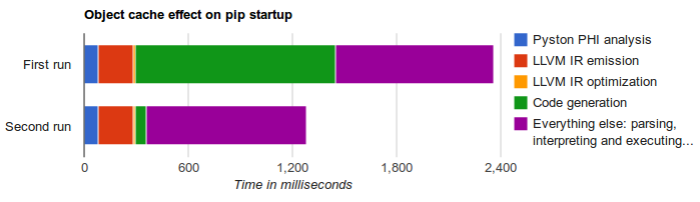
The result is that we cut the time to JIT the functions down to 350ms (was 1.4secs) of those merely 60ms are actually spend hashing the IR, decompressing and loading the object code and relocating the pointers (down from 1.1secs).
I think this is a good example of what quite significant performance enhancements can be made with a small amount of effort. There is a lot of room for improvements to this simple caching mechanism for example we could use it for a new ahead-of-time compile mode for important code (e.g the standard Python library) using a higher optimization level. While this change alone will not eliminate all of LLVMs higher JITing cost we are excited to implement additional features and performance optimizations inside Pyston.
If you are interested in more detailed performance statistics pass “-s” to Pyston’s command line and you will see much more output but you may have to look into the source code to see what every stat entry measures.
