For a list of common questions about our project, please see our FAQ.
We are very excited to release Pyston 0.4, the latest version of our high-performance Python JIT. We have a lot to announce with this release, with the highlights of being able to render Dropbox webpages, and achieve performance 25% better than CPython (the main Python implementation) on our benchmark suite. We are also excited to unveil our project logo:

A lot has happened in the eight months since the 0.3 release: the 0.4 release contains 2000 commits, three times as many commits as either the 0.2 or 0.3 release. Moving forward, our plan is to release every four months, but for now please enjoy a double-sized release.
Compatibility
While not individually headline-worthy, this release includes a large number of new features:
- Unicode support
- Multiple inheritance
- Support for weakrefs and finalizers (__del__), including proper ordering
- with-statements
- exec s in {}
- Mutating functions in place, such as by setting func_code, func_defaults, or func_globals
- Import hooks
- Set comprehensions
- Much improved C API support
- Better support for standard command line arguments
- Support for multi-line statements in the REPL
- Traceback and frame objects, locals()
Together, these mean that we support almost all Python semantics. In addition, we’ve implemented a large number of things that aren’t usually considered “features” but nonetheless are important to supporting common libraries. This includes small things such as supporting all the combinations of arguments builtin functions can take (passing None as the function to map()) or “fun” things such as mutating sys.modules to change the result of an import statement.
Together, these new features mean that we support many common libraries. We successfully run the test suites of a number of libraries such as django and sqlalchemy, and are continually adding more. We have also started running the CPython test suite and have added 153 (out of 401) of their test files to our testing suite.
We also have some initial support for NumPy. This isn’t a priority for us at the moment (our initial target codebase doesn’t use NumPy), but we spent a small amount of time on it and got some simple NumPy examples working.
And most importantly, we now have the ability to run the main Dropbox server, and can render many of its webpages. There’s still more work to be done here — we need to get the test suite running, and get a performance-testing regimen in place so we can start reporting real performance numbers and comparisons — but we are extremely happy with the progress here.
C API
One thing that has helped a lot in this process is our improved C API support. CPython has a C API that can be used for writing extension modules, and starting in the 0.2 release we added a basic compatibility layer that translated between our APIs and the CPython ones. Over time we’ve been able to extend this compatibility to the point that not only can we support C extensions, but we also support running CPython’s internal code, since it is written to the same API. This means that to support a new API function we can now use CPython’s implementation of the function rather than implementing it on top of our APIs.
As we’ve implemented more and more APIs using CPython’s implementation, it’s become hard to continue thinking of our support as a compatibility layer, and it’s more realistic to think of CPython as the base for our runtime rather than a compatibility target. This has also been very useful towards our goal of running the Dropbox server: we have been able to directly use CPython’s implementation of many tricky features, such as unicode handling. We wouldn’t have been able to run the Dropbox server in this amount of time if we had to implement the entire Python runtime ourselves.
Performance
We’ve made a number of improvements to Pyston’s performance, including:
- Adding a custom C++ exception unwinder. This new unwinder takes advantage of Pyston’s existing restrictions to make C++ exceptions twice as fast.
- Using fast return-code-based exceptions when we think exceptions will be common, either due to the specifics of the code, or due to runtime profiling.
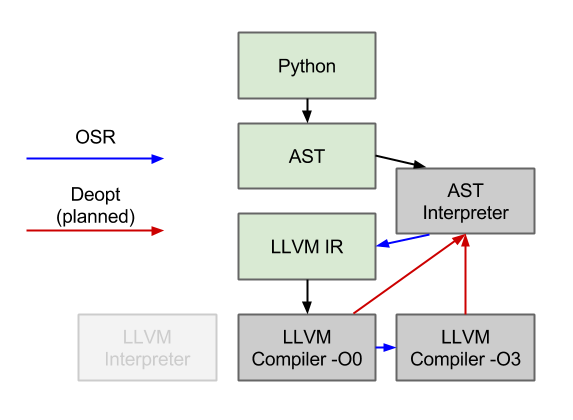
- A baseline jit tier, which sits between the interpreter and the LLVM JIT. This tier approaches the performance of the LLVM tier but has much lower startup overhead.
- A new on-disk cache that eliminates most of the LLVM tier’s cost on non-initial runs.
- Many tracing enhancements, producing better code and supporting more cases
- New CAPI calling conventions that can greatly speed up calling CAPI functions.
- Converted some builtin modules to shared modules to improve startup time.
- Added a PGO build, and used its function ordering in normal builds as well.
Conspicuously absent from this list is better LLVM optimizations. Our LLVM tier has been able to do well on microbenchmarks, but on “real code” it tends to have very little knowledge of the behavior of the program, even if it knows all of the types. This is because knowing the types of objects only peels away the first level of dynamicism: we can figure out what function we should call, but that function will itself often contain a dynamic call. For example, if we know that we are calling the len() function, we can eliminate the dynamic dispatch and immediately call into our implementation of len() — but that implementation will itself do a dynamic call of arg.__len__(). While len() is common enough that we could special-case it in our LLVM tier, this kind of multiple-levels-of-dynamicism is very common, and we have been increasingly relying on our mini tracing JIT to peel away all layers at once. The result is that we get good execution of each individual bytecode, but the downside is that we are currently lacking good inter-bytecode optimizations. Our plan is to integrate the per-bytecode tracing JIT and the LLVM method JIT to achieve the best of both worlds.
Benchmarks
We updated our benchmarks suite to use three real-world libraries: our suite contains a benchmark based on each of pyxl, django, and sqlalchemy. Benchmark selection is a contentious topic, but we like these benchmarks because they are more typical of web servers than existing Python benchmark suites.
On these benchmarks, we are 25% faster than CPython (and 25% slower than PyPy 4.0.0). We have a full performance tracking site, where you can see our latest benchmark results (note: that last link will auto-update over time and isn’t comparing the same configurations as the 25% result).
Community
We also have a number of exciting developments that aren’t directly related to our code:
- We switched from a Makefile build system to a CMake-based one. This lets us have some nice features such as a configure step, faster builds (by supporting Ninja), and down the road easier support for new platforms. This was done by an open source contributor, Daniel Agar, and we are very thankful!
- We have more docs. Check out our wiki for some documentation on internal systems, or tips for new contributors. Browsing the codebase should be easier as well.
- We have a logo!
- We had 184 commits from 11 open source contributors. A special shoutout to Boxiang Sun, who has greatly helped with our compatibility!
Final words
We have a pre-built binary available to download on Github (though please see the notes there on running it). Pyston is still in a pre-launch state, so please expect crashes or occasional poor performance, depending on what you run it on. But if you see any of that, please let us know either in our Gitter channel or by filing a Github issue. We’re excited to hear what you think!
If you are in the Bay Area, we are having a talk + meetup at the Dropbox SF office at 6:30pm on November 10th. We only have a few spaces left, so please RSVP if you are interested. More details at the RSVP link.
We have a lot of exciting things planned for our 0.5 series as well. Our current goals are to implement a few final features (such as inspection of stack frames after they exit), to continue improving performance, and to start running some Dropbox services on Pyston. It’s an exciting time, and as always we are taking new contributors! If you’re interested in contributing, feel free to peruse our docs, check out our list of open issues, or just say hi!